Master's in Data Science
USF - University of San Francisco
Deep Learning, Machine Learning, Forecasting, Statistics, Spark, Computational Linear Algebra, Design of Experiments

About Me
I'm currently finishing my Master's of Data Science (MSDS) at the University of San Francisco. My current studies focus on machine learning, distributed computing, and deep learning.
I am currently working as a Data Science Research Intern in the cyber security industry at Endgame. I use machine learning to detect hidden computer viruses, and set up specialty data pipelines to ingest millions of malicious files each day
I've also previously had an Data Science internship at a brand marketing firm AKQA. Designed proof-of-concept machine learning products for next-gen service offerings.
Previously I've been a Analytics Manager in PwC Consulting working with Fortune 500 clients to provide analytic insights using python and SQL to cut through billion-row databases.
And before that I was a Lead Structural Engineer in Rolls Royce designing custom materials and parts for supersonic + space flight.
My Outputs


Combined manual survey data, metered parking data, and magnetic motion data to create a generalized parking prediction model for San Francisco. Gradient Boosting. Matrix Factorization. Clustering.

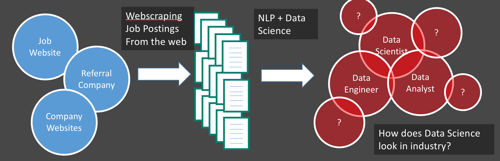

Scraped 30k+ job postings for data scientsts, data analysts, and data engineer to cluster around job requirements and keywords. Latent Dirichet Allocation. Scrapy. Spacy. TFIDF. Logistic Regression.

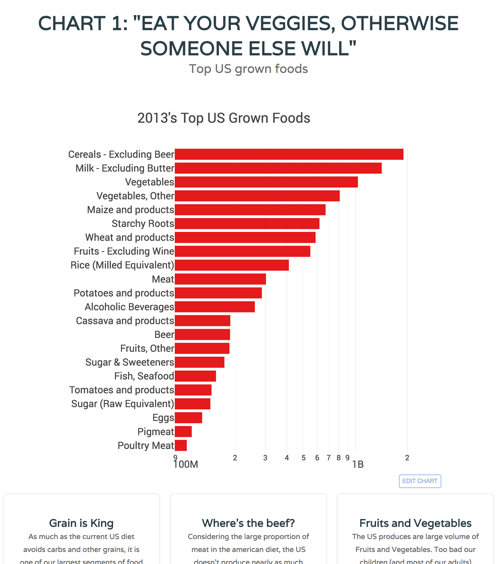
Using World Bank Data, the World Trade Data, and used thoughtful visualization to understand international trade and industrial production Python Flask. Plotly. Pandas. Seaborn. Scrapy
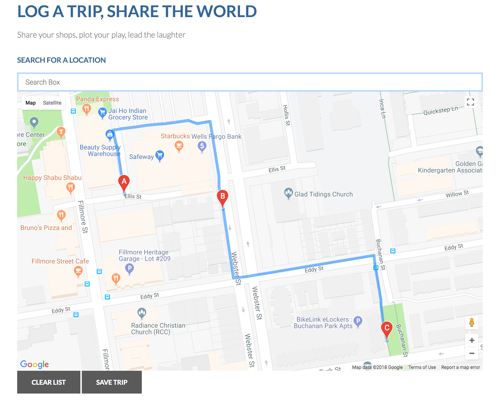
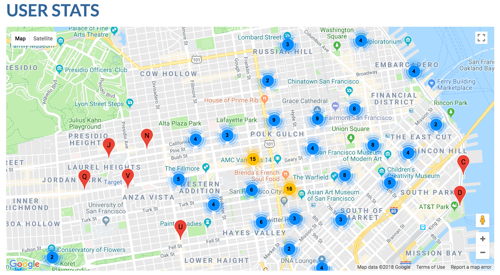
Built a python web app + android client so that users can log their trips throughout the city and easily share them with friends and family. It could be a scenic walk along the coast, a great bar crawl, or a secret street that has a great xmas lights show. Django. Plotly. GoogleMaps API. Seaborn. Scrapy

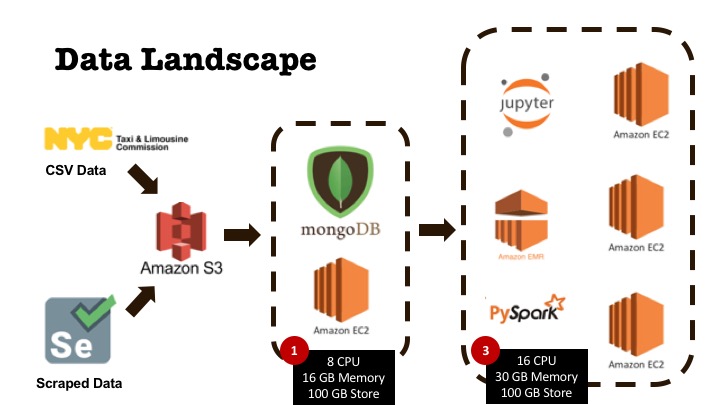
Set up a Apache Spark Cluster to run machine learning benchmarking tests for regression, classification and clustering. PySpark. AWS EMR, Apache Spark. Yarn. MlLib
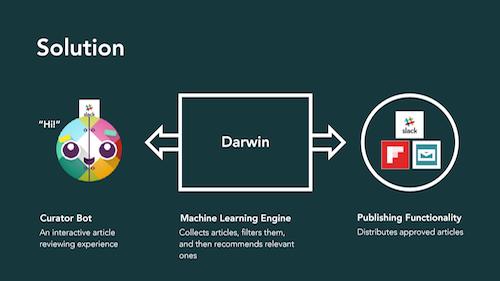

Designed a slack bot that will 1. act as an interactive news delivery system, and will 2. take your feedback to give better recommendations. Stored user feedback to improve machine learning models. Users can suggest their own topics, and recommender gets better over time with more feedback. Botkit. React JS. Non-negative Matrix Factorization. Latent Dirichet Allocation. TSNE. Selenium

Unsupervised analysis of Yelp reviewers in the Arizona area. Used exploratory data analysis with data visualation and K-means clustering techniques to understand users. Exploratory data analysis. K-means Clustering.

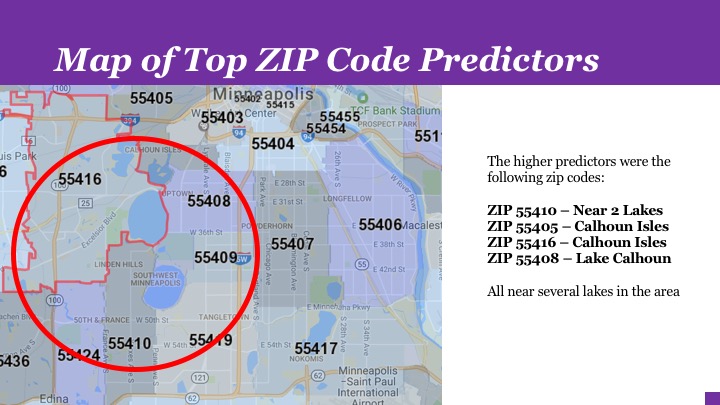
Analyzed housing prices in Minnesota and built a regression model to predict future prices. Linear Regression. Regularization. Feature Engineering
My Inputs

USF - University of San Francisco
Deep Learning, Machine Learning, Forecasting, Statistics, Spark, Computational Linear Algebra, Design of Experiments
UCLA - University of California in Los Angeles
Computational Stress
Finite Element Modeling
Numerical Approximations.

UCLA - University of California in Los Angeles
Mechanism Design
Manufacturing
General Assembly SF, Coursera
GA Data Science
Coursera Stanford Machine Learning
Coursera Stanford Deep Learning
How to reach me